Many Etleap customers are considering a data mesh. The approach, increasingly popular among large enterprises, includes decentralizing control of data and analytics to individual business teams, or domains. Some functions remain centrally managed, including what the data mesh literature calls a self-serve data platform.
We appreciate the motivations behind a data mesh and think it is ideal for some organizations. However, we feel strongly that if organizations over-rotate to decentralization, they risk leaving domain teams unsupported and ultimately fostering a dysfunctional data mesh. In this blog we’ll provide an overview of the data mesh and what leads organizations to consider one, and we’ll argue that the data mesh’s self-serve platform needs to be far more ambitious.
Data mesh decentralization: How did we get to this?
We can thank Thoughtworks’ Zhamak Dehghani for all this discussion about data mesh. Her 2019 talk “Beyond the lake” formulated the ideas, and more recently she has expanded the details into the full-length Data Mesh book. If you’re on the data mesh path, we highly recommend you give it a read.
Data mesh’s first principle is decentralized domain ownership.
“Data mesh, at its core, is founded in decentralization and distribution of data responsibility to people who are closest to the data.”
-Zhamak Dehgani, Data Mesh
Why has data mesh’s decentralization resonated so strongly with data leaders? Despite the technology gains that enable limitless data centralization, most organizations have yet to operationalize that to deliver timely, effective value from data.
Historically, the path from raw data to analytics value went through a central team of ETL and data warehouse specialists. The tools and specialists were costly, so only the largest organizations could even entertain organization-wide analytics. Those that did adopt a data warehouse still had to be judicious about what data to include so they could keep costs under control.
Data lakes and cloud data warehouses have drastically brought down processing and storage costs, and it is now possible to aggregate nearly infinite volumes of data. This has coincided with an explosion of data volumes of varying types, and this era of big data brought us closer to the promise of providing all of an organization’s data to all of its potential users.
The big remaining hurdle, though, has been to make this data actually usable and not end up with the murky data swamp. Central teams can scale data repositories to the petabyte range, but what is harder to scale is incorporating the necessary context and expertise with the data. This knowledge sharing has always been an integral partnership between the business domains and a central data team. For most organizations, the sharing hasn’t kept pace with data growth.
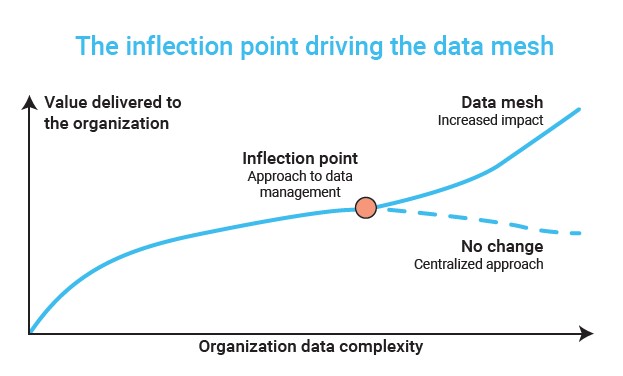
It’s not surprising that these domains see a potential answer in a decentralized approach. Dehghani describes a data management inflection point. Centralization delivers increasing impact with larger and more complex organization requirements, but only up to a point.
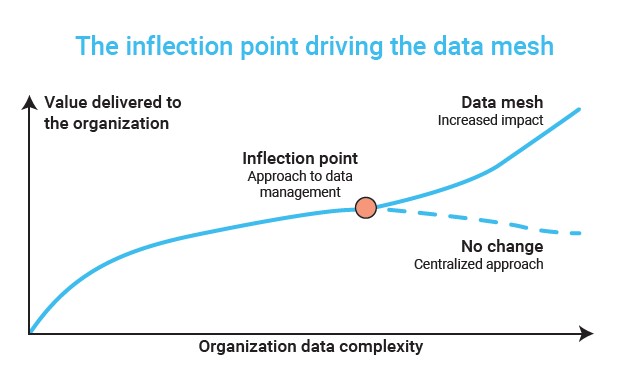
Beyond a certain level of complexity, diversity of data use cases, and ubiquitous sources, it becomes fruitless for the organization to continue centralizing data and its control.
Where does decentralizing leave the central data team?
Decisions about what to centralize and decentralize are neither new nor unique to the data world. There are typically tradeoffs in each centralization choice and rarely one-size-fits-all approaches.
Dheghani highlights two immediate risks of swinging the pendulum to decentralization: incompatibility and inefficiency. If domains develop independent platforms, we will return to data silos and impede essential cross-domain data products and analytics. Each domain building its own data environment and team is costly and inefficient, sacrificing the benefits of an organization’s scale.
Dehghani addresses these risks in her remaining principles. Treating data as a product ensures that domains provide analytics-ready data for the larger organization. Federated governance balances the independence of the domains with the interoperability of the mesh, detailing policies applicable to all domains.
The principle of the self-serve data platform also touches on both risks, adding some efficiency in a central platform that also ensures compatibility and integration between domains. The central team must provide this platform for a baseline of consistency and interoperability.
What do they mean, self-serve?
A central data platform is meant to provide the basic infrastructure so that domain teams do not try to build or purchase every tool and functionality to generate analytics insights. Dehghani encourages those providing a self-serve data platform to build it for the “generalist majority.”
"Many organizations today are struggling to find data specialists such as data engineers, while there is a large population of generalist developers who are eager to work with data. The fragmented, walled, and highly specialized world of big data technologies have created an equally siloed fragment of hyper-specialized data technologists."
-Zhamak Dehgani, Data Mesh
Dehghani correctly identifies the market shortage of data engineers and the impractical goal of staffing them on domain teams. Instead, domain teams should rely on “generalist developers” to consume the centralized infrastructure and build upon it.
We believe a platform that requires domain developers and coding is still an unnecessarily high barrier to success. For a data mesh to succeed, central teams need to raise the bar for self service, giving domains a simple, end-to-end path from source to analytics.
Self-serve can't mean DIY: it must be more "serve" than "self"
Self-serve conveys different things to different people. For some, it’s a grab-and-go lunch and for others it’s a do-it-yourself IKEA-style assembly project. There are domains that are highly technical and set out to build data infrastructure that matches or exceeds the capabilities of what a central team might build.
But for an organization to gain value from a data mesh, it needs buy-in and adoption from more than just a couple of ambitious domains. If only the most data savvy domains make the leap, the organization hasn’t outperformed centralization - they’ve just moved the controls, and perhaps the headcount.
The central team, therefore, must deliver a service and infrastructure where domains can be productive quickly, without needing developers. Below we detail the essentials of such a platform, from underlying compute scaling to source and destination integration and transformation to ongoing monitoring and management. With these in place, the domains can focus on data and analytics, quickly moving past setup and pipeline management.
Managed compute infrastructure
For starters, the central team should abstract away the details of the core compute and storage infrastructure from the domains. Configuring frameworks and elastically spinning up and down compute resources should be centralized. From a data pipeline perspective, domains should provide parameters of their latency requirements, but otherwise expect the platform to seamlessly adapt to changing data volumes.
Out-of-the box data source ingestion
Each domain has its own data sources, including files, databases, SaaS applications, and more. The central team must provide a platform to ingest data from these into an analytics infrastructure without requiring any code. Even for unique, proprietary data sources, the domains shouldn’t be left to code these integrations on their own.
No-code transformation
In moving data from the operational to the analytical plane, providing transformation capability is essential. Domain teams will have varied skills, and the data transformation options should reflect that. Centralized teams of ETL specialists have historically struggled to keep up with business domain needs. The answer is not to shift that complexity and specialist coding decentrally. Instead, domains should have a user-friendly interface for connecting data sources (extract) with analytics destinations (load). The no-code approach should also include transformations, with a data wrangler to help analysts visually prepare data for analytics consumption. Tooling should also serve domains where users are able to code in SQL, Python, Scala and other languages, but these skills should not be required.
Dependable pipeline management
Though a data mesh pushes many controls out to the domains, the central team must still ensure data pipeline uptime and performance. Absent such support, the domains will get bogged down checking pipeline results, reacting to schema changes, and endlessly troubleshooting. The central platform should include automated issue detection, alerting, and resolution, where possible. When domain input is needed, the central team should efficiently facilitate guided solutions.
Simple yet thorough configurability
While the central team needs to prioritize simple-to-use, automation-first approaches, it also needs to capture domain input and adjust accordingly. Users must be able to configure their pipelines for scheduling, dependency management, error tolerance thresholds, to name a few. The platform should have the flexibility to integrate domain-specific processes like data quality.
With this truly self-serve data platform, domains easily select their data sources, choose scheduling options, visually define necessary transformations, and know that pipelines will just work from there. In a matter of hours, they should move beyond data movement and on to analyzing or publishing their data products. Central teams can empower a data-driven organization with an effective data mesh if they can deliver this platform.
A managed pipeline service behind your self-serve data platform
The ability to serve every unique domain in a data mesh while cutting their engineering burden is a challenging balance. From our beginnings, Etleap has focused on that same challenge, and our diverse customers now benefit from those years of effort and learning. So you won’t be surprised to hear that Etleap delivers the data pipeline capabilities of a self-serve platform out of the box.
Central teams can deploy Etleap and offer quick adoption and value within hours of domain onboarding. Business users and coders alike can select their data sources, designate their analytics destination, customize a schedule, and transform data with a visual wrangler. Neither domain team nor central team has to build connectors or write code for monitoring or alerting. Etleap provides all of this as a service, and pipeline management is seamless and reliable. The central team can also use Etleap’s extension points to create data catalog, quality, lineage, and other functionality across the wider organization.
The data mesh should accelerate the path of data from its sources to those who can generate insights and value from it. We’ve seen organizations that get data mesh right. When central teams and platforms can facilitate domains to deliver on their expertise - rather than one team trying to do it all - it’s an inspiring combination!