This blog post was written in partnership with the Amazon Redshift team, and also posted on the AWS Big Data Blog.
Amazon Redshift Serverless lets you avoid managing infrastructure while only paying for what you use. Etleap provides data integration software that is natively built on AWS. It’s an AWS Advanced Technology Partner with the AWS Data & Analytics Competency and Amazon Redshift Service Ready designation.
In this post, we share how you can minimize the usage of resources for some workload patterns and maximize savings while seamlessly managing data pipelines. We illustrate an example of how Redshift Serverless and Etleap’s load synchronization feature can reduce active Redshift Serverless time, further optimizing extract, transform, and load (ETL) costs.
Introduction to Redshift Serverless
Redshift Serverless makes it easy to run and scale analytics in seconds without the need to set up and manage data warehouse clusters. With Redshift Serverless, you pay for the compute only when the data warehouse is in use. This is ideal when it’s difficult to predict compute needs such as variable workloads, periodic workloads with idle time, and steady-state workloads with spikes. As your demand evolves with new workloads and more concurrent users, Redshift Serverless automatically provisions the right compute resources, and your data warehouse scales seamlessly and automatically.
You can create a Redshift Serverless data warehouse either using the default settings or custom settings. Redshift Serverless creates a default workgroup and associates that to the default namespace. You can also create multiple Redshift Serverless endpoints per AWS account and Region using namespaces and workgroups.
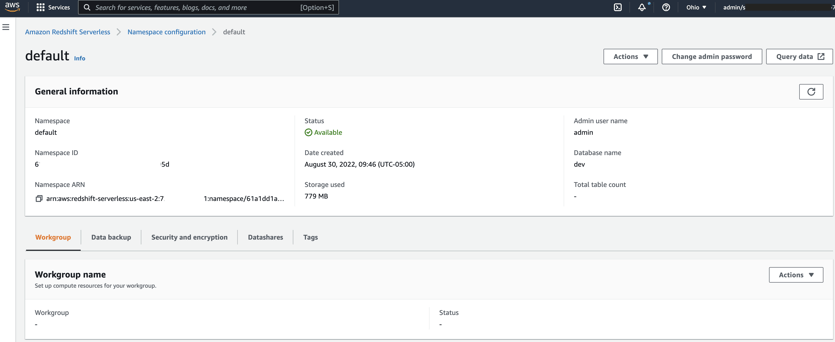
A namespace is a collection of database objects and users, with properties such as database name and password, permissions, and encryption and security. The following screenshot shows an example of a namespace configuration on the Redshift Serverless console.
A workgroup is a collection of compute resources, which includes network and security settings. Workgroup configuration allows you to create a private or public serverless endpoint that you can use to connect with your applications. The following screenshot shows an example workgroup on the Redshift Serverless console.
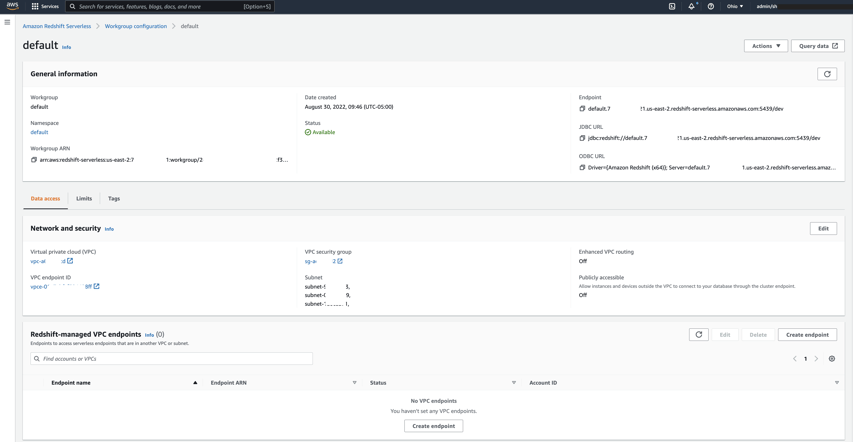
When the Redshift Serverless endpoint is available, choose Query data to launch the Amazon Redshift Query Editor v2 to create database objects, load data, and analyze and visualize data. You can also connect to Redshift Serverless endpoints using your preferred SQL client tools via Amazon Redshift JDBC/ODBC drivers.
With Redshift Serverless, you pay separately for the compute and storage you use. Compute capacity is measured in Redshift Processing Units (RPUs), and you pay for the workloads in RPU-hours with a minimum charge of 60 seconds, metered on a per-second basis. Data lake queries are also part of the same RPU-hours, and Redshift Serverless doesn’t charge separately for the per-TB based pricing of Amazon Redshift Spectrum. The default base capacity is 128 RPUs, but you can adjust it from 32 RPUs to 512 RPUs in units of 8 using the Redshift Serverless console. For storage, you pay for data stored in Amazon Redshift-managed storage and storage used for manual snapshots, similar to what you would pay with Amazon Redshift provisioned RA3 instances.
To control your costs, you can specify usage limits and define actions that Amazon Redshift automatically takes if those limits are reached. You can specify usage limits in RPU-hours and associated with a daily, weekly, or monthly duration. Setting higher usage limits can improve the overall throughput of the system, especially for workloads that need to handle high concurrency while maintaining consistently high performance.
Why Etleap customers need Redshift Serverless
Etleap gives customers robust and flexible pipelines without the hassle of coding and managing infrastructure. Redshift Serverless has a similar benefit, letting you run Amazon Redshift without worrying about provisioning and maintaining data warehouse.
With the close Etleap-AWS integration, you can get started working with multiple data sources in Redshift Serverless in minutes.
Redshift Serverless can also reduce users’ costs because it automatically scales data warehouse capacity up and down to match usage and only charges when the serverless instance is active. ETL workloads are often batch-based and characterized by spikes, so the dynamic scaling of Redshift Serverless reduces unnecessary costs.
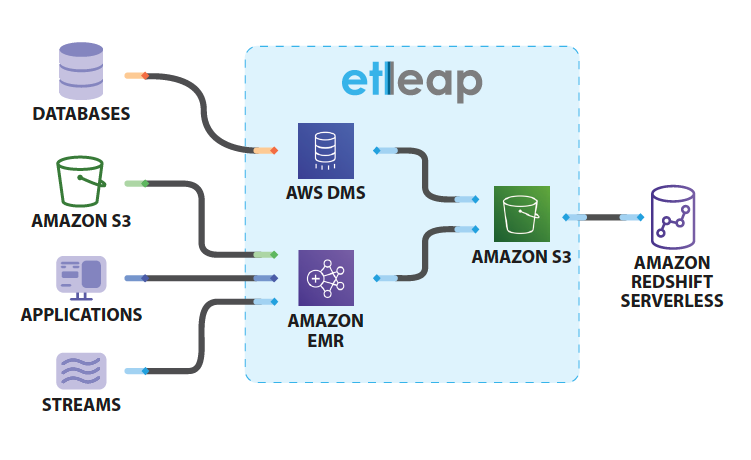
The following diagram illustrates this solution architecture.
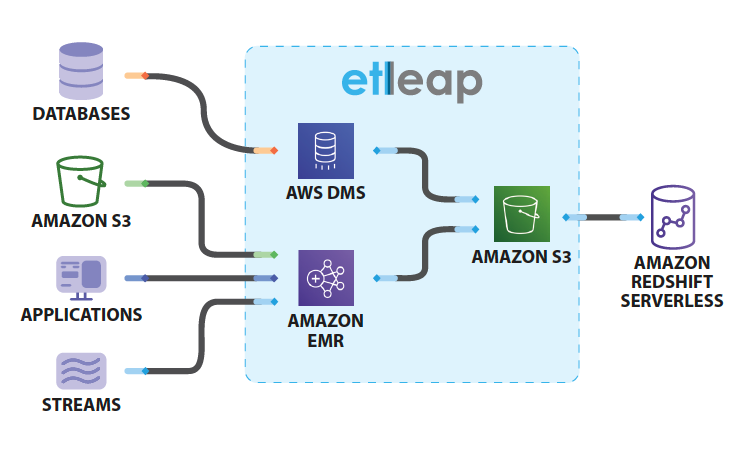
Etleap uses Amazon Database Migration Service (AWS DMS), Amazon EMR, and Amazon Simple Storage Service (Amazon S3) to process data from databases, files, applications, and streams into Redshift Serverless.
Optimize costs for Redshift Serverless
One of the main sources of cost savings when using Redshift Serverless comes from its auto-pausing feature. When a Redshift Serverless instance is idle, it will auto-pause and you aren’t charged during this period of inactivity.
However, high frequency ETL pipelines (such as those from streams or CDC sources) can constantly resume the Redshift Serverless instance, negating the cost benefit. To maximize the advantages of the auto-pausing feature of Redshift Serverless, Etleap provides the option of load synchronization. As shown in the following figure, this reduces the number of load batches, thereby lowering active Redshift Serverless instance time and cost.
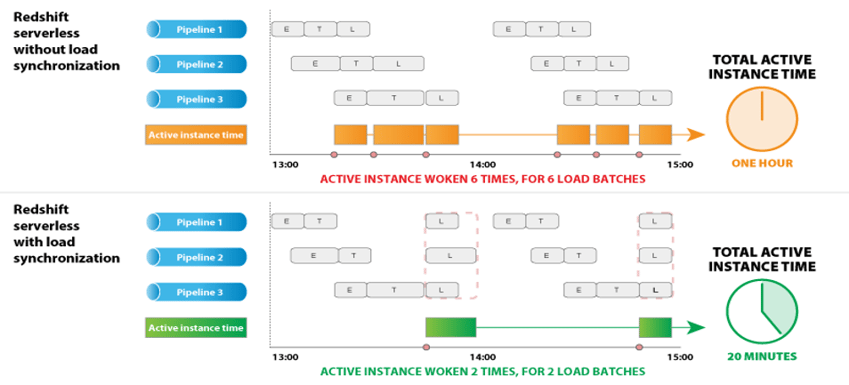
It sometimes makes sense to maximize the frequency of data ingestion, but not all use cases justify the higher cost of an always-on Amazon Redshift instance. Etleap users can set their load frequency at a cost-efficient once-per-hour or as frequently as every 5 minutes.
Amazon Redshift users typically run some SQL transformations after data is loaded in the warehouse. Etleap’s models feature lets you define the SQL transformations and their dependencies and control when these transformations are run. As with data loading, however, if these aren’t designed thoughtfully, there is a risk that models will trigger updates that unnecessarily wake up an idle Redshift Serverless instance, negating the cost savings of the Redshift Serverless auto-pausing feature.
To avoid this, Etleap schedules the models to update immediately after all the dependent tables have been updated. This maximizes the instance usage while it’s awake and allows it to pause when the loads and updates have completed.
Cost savings example
Let’s illustrate the cost savings benefits of Redshift Serverless by means of an example. A customer has set a 1-hour load synchronization schedule and has 100 pipelines and 10 models. Although by default Redshift Serverless has a provisioned base capacity of 128 RPUs, a provisioned base capacity of 32 RPUs is sufficient for the load requirements of this example. A typical average load time for Etleap customers into Amazon Redshift is 6 seconds. In Etleap, we perform a maximum of five loads at a time to avoid overloading the Redshift Serverless instance.
Here is an example of how the sequence would work for the pipelines:
- When the hourly schedule triggers, Etleap begins the extraction and transformation of source data for all pipelines with new data to process.
- After all the pipelines have finished extraction and transformation, Etleap begins to load the data into Amazon Redshift. This resumes the serverless instance. At an average of 6 seconds per load and five loads running in parallel, it takes 120 seconds to load all the pipelines (100 / 5 pipeline cycles * 6 seconds each).
- When the load is complete, Etleap triggers the model updates. A typical model in Etleap takes about 130 seconds to update. As with loads, Etleap limits models to five simultaneous updates to reduce the load on the Redshift Serverless instance. Therefore, updating all 10 models takes 260 seconds of total instance run time (130 seconds * 10/5 model cycles).
- At this point, you’re being charged for 380 seconds of active workload, and Redshift Serverless will become idle after some time.
Additionally, Etleap runs daily vacuum operations on applicable tables to minimize storage and improve query efficiency. The length of this process depends on the tables and the number of updates and deletes. For a customer with this amount of pipeline volume, 20 minutes is a typical length of time to vacuum the tables, adding that much daily runtime for the instance.
This results in a total daily runtime of 172 minutes ((380 seconds * 24 daily cycles / 60) + 20 minutes), which translates into a cost of $34.40 per day for a 32 RPU serverless instance. This is 88% lower cost than a comparable Amazon Redshift provisioned environment without the benefits of Etleap and Redshift Serverless: an always-on provisioned Amazon Redshift cluster with similar performance (1 year reserved instance pricing for 16 ra3.xlplus nodes running 24 hours/day).
Other ETL optimizations on Etleap using Redshift Serverless
Etleap natively supports Redshift Serverless by updating its ETL solution to ensure you can continue to seamlessly ingest diverse data sources.
Redshift Serverless offers new system views that are used for tracking and managing ingestion, and Etleap utilizes these new system views to natively handle tracking ingestion loads and vacuuming operations in their platform. For example, Etleap uses sys_query_history to determine which loads are in progress or complete, and thereby helps avoid double loading a batch.
Redshift Serverless automatically initiates optimizations such as sort and vacuum in the background and doesn’t charge for these automatic optimizations. As a best practice, after Etleap load synchronization, Etleap periodically runs the vacuum function on applicable tables, which reduces storage and improves query performance. Etleap uses the vacuum_sort_benefit column in svv_table_info, which provides the statistics for each table, informing which would benefit from vacuuming.
Summary
In this post, we described how Redshift Serverless frees you from managing data warehouse infrastructure and reduces costs. In particular, we illustrated a data integration pattern where Etleap can ensure further cost savings through its load synchronization feature by optimally choosing a cost-efficient once-per-hour load frequency. Although this proves to be an optimal solution for uses cases where you prefer cost efficiency over real-time data insights, Etleap also allows you to set the load frequency as low as 5 minutes for use cases where near-real-time data insights are important.
Start using Redshift Serverless to run and scale analytics without having to manage data warehouse infrastructure and take advantage of further cost savings through Etleap’s load synchronization feature. To get started with Etleap, start a free trial or request a tailored demo.
About the authors
 Caius Brindescu is an engineer at Etleap with over 4 years of experience in developing ETL software. In addition to development work, he helps customers make the most out of Etleap and Amazon Redshift. He holds a PhD from Oregon State University and one AWS certification (Big Data – Specialty).
Caius Brindescu is an engineer at Etleap with over 4 years of experience in developing ETL software. In addition to development work, he helps customers make the most out of Etleap and Amazon Redshift. He holds a PhD from Oregon State University and one AWS certification (Big Data – Specialty).
 Maneesh Sharma is a Senior Database Engineer at AWS with more than a decade of experience designing and implementing large-scale data warehouse and analytics solutions. He collaborates with various Amazon Redshift Partners and customers to drive better integration.
Maneesh Sharma is a Senior Database Engineer at AWS with more than a decade of experience designing and implementing large-scale data warehouse and analytics solutions. He collaborates with various Amazon Redshift Partners and customers to drive better integration.
 Sathisan Vannadil is a Senior Partner Solutions Architect at Amazon Web Services (AWS). His primary focus is on helping independent software vendor (ISV) partners design and build solutions at scale on AWS. Prior to AWS, Sathisan held diverse technical positions and has over 20 years of experience in the field of data and analytics.
Sathisan Vannadil is a Senior Partner Solutions Architect at Amazon Web Services (AWS). His primary focus is on helping independent software vendor (ISV) partners design and build solutions at scale on AWS. Prior to AWS, Sathisan held diverse technical positions and has over 20 years of experience in the field of data and analytics.