This blog post was written in partnership with the Amazon Redshift team, and also posted on the AWS Big Data Blog.
Organizations use their data to extract valuable insights and drive informed business decisions. With a wide array of data sources, including transactional databases, log files, and event streams, you need a simple-to-use solution capable of efficiently ingesting and transforming large volumes of data in real time, ensuring data cleanliness, structural integrity, and data team collaboration.
In this post, we explain how data teams can quickly configure low-latency data pipelines that ingest and model data from a variety of sources, using Etleap’s end-to-end pipelines with Amazon Redshift and dbt. The result is robust and flexible data products with high scalability and best-in-class query performance.
INTRODUCTION TO AMAZON REDSHIFT
Amazon Redshift is a fast, fully-managed, self-learning, self-tuning, petabyte-scale, ANSI-SQL compatible, and secure cloud data warehouse. Thousands of customers use Amazon Redshift to analyze exabytes of data and run complex analytical queries. Amazon Redshift Serverless makes it straightforward to run and scale analytics in seconds without having to manage the data warehouse. It automatically provisions and scales the data warehouse capacity to deliver high performance for demanding and unpredictable workloads, and you only pay for the resources you use. Amazon Redshift helps you break down the data silos and allows you to run unified, self-service, real-time, and predictive analytics on all data across your operational databases, data lake, data warehouse, and third-party datasets with built-in governance. Amazon Redshift delivers up to five times better price performance than other cloud data warehouses out of the box and helps you keep costs predictable.
INTRODUCTION TO DBT
dbt is a SQL-based transformation workflow that is rapidly emerging as the go-to standard for data analytics teams. For straightforward use cases, dbt provides a simple yet robust SQL transformation development pattern. For more advanced scenarios, dbt models can be expanded using macros created with the Jinja templating language and external dbt packages, providing additional functionality.
One of the key advantages of dbt is its ability to foster seamless collaboration within and across data analytics teams. A strong emphasis on version control empowers teams to track and review the history of changes made to their models. A comprehensive testing framework ensures that your models consistently deliver accurate and reliable data, while modularity enables faster development via component reusability. Combined, these features can improve your data team’s velocity, ensure higher data quality, and empower team members to assume ownership.
dbt is popular for transforming big datasets, so it’s important that the data warehouse that runs the transformations provide a lot of computational capacity at the lowest possible cost. Amazon Redshift is capable of fulfilling both of these requirements, with features such as concurrency scaling, RA3 nodes, and Redshift Serverless.
To take advantage of dbt’s capabilities, you can use dbt Core, an open-source command-line tool that serves as the interface to using dbt. By running dbt Core along with dbt’s Amazon Redshift adapter, you can compile and run your models directly within your Amazon Redshift data warehouse.
INTRODUCTION TO ETLEAP
Etleap is an AWS Advanced Technology Partner with the AWS Data & Analytics Competency and Amazon Redshift Service Ready designation. Etleap simplifies the data pipeline building experience. A cloud-native platform that seamlessly integrates with AWS infrastructure, Etleap consolidates data without the need for coding. Automated issue detection pinpoints problems so data teams can stay focused on analytics initiatives, not data pipelines. Etleap integrates key Amazon Redshift features into its product, such as streaming ingestion, Redshift Serverless, and data sharing.
In Etleap, pre-load transformations are primarily used for cleaning and structuring data, whereas post-load SQL transformations enable multi-table joins and dataset aggregations. Bridging the gap between data ingestion and SQL transformations comes with multiple challenges, such as dependency management, scheduling issues, and monitoring the data flow. To help you address these challenges, Etleap introduced end-to-end pipelines that use dbt Core models to combine data ingestion with modeling.
ETLEAP END-TO-END DATA PIPELINES
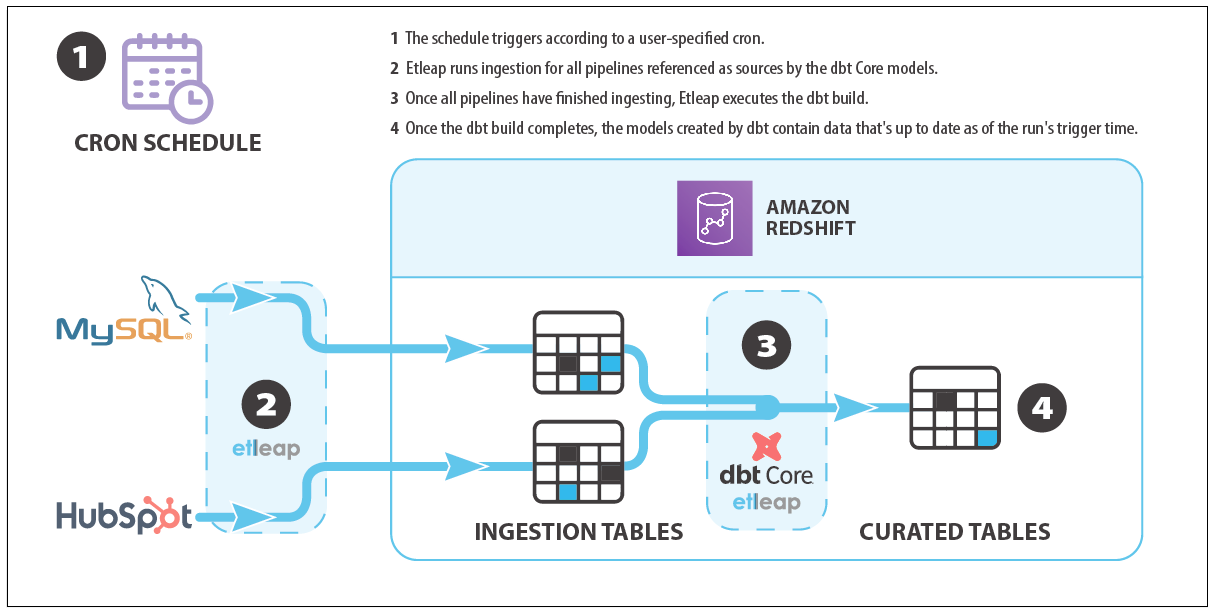
The following diagram illustrates Etleap’s end-to-end pipeline architecture and an example data flow.
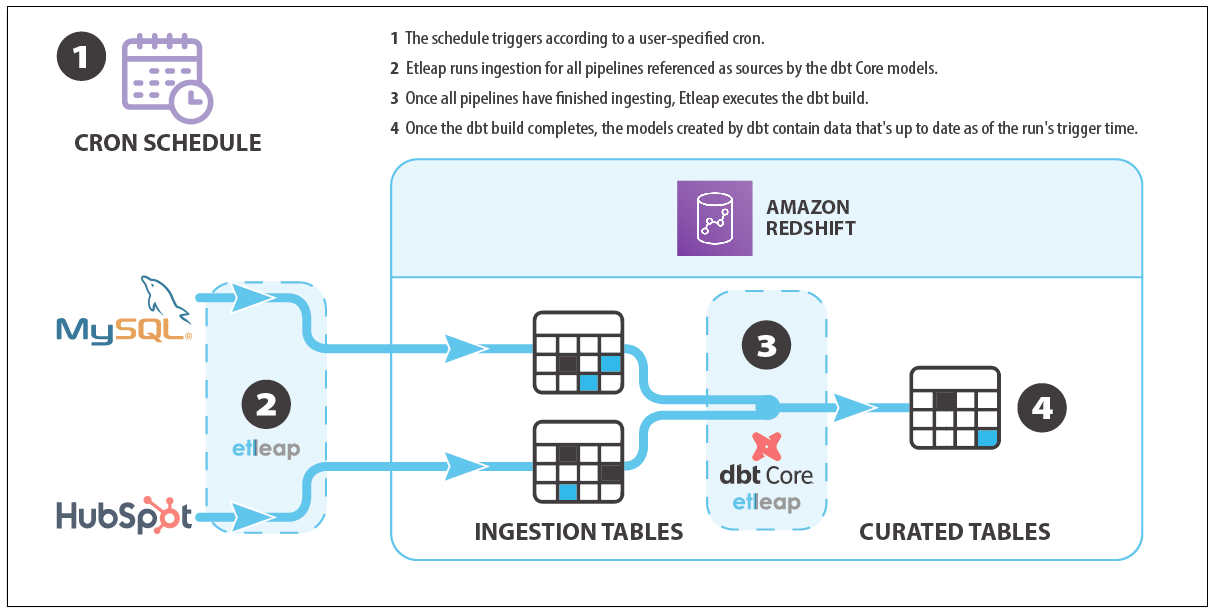
Etleap end-to-end data pipelines combine data ingestion with modeling in the following way: a cron schedule first triggers ingestion of data required by the models. Once all the ingestion is complete, a user-defined dbt build is run, which performs post-load SQL transformations and aggregations on the data that has just been ingested by ingestion pipelines.
End-to-end pipelines offer several advantages over running dbt workflows in isolation, including dependency management, scheduling and latency, Amazon Redshift workload synchronization, and managed infrastructure.
DEPENDENCY MANAGEMENT
In a typical dbt use case, the data that dbt performs SQL transformations on is ingested by an extract, transform, and load (ETL) tool such as Etleap. Tables ingested by ETL processes in dbt projects are usually referenced as dbt sources. Those source references need to be maintained either manually or using custom solutions. This is often a laborious and error-prone process. Etleap eliminates these processes by automatically keeping your dbt source list up to date. Additionally, any changes made to the dbt project or ingestion pipeline will be validated by Etleap, ensuring that the changes are compatible and won’t disrupt your dbt builds.
SCHEDULING AND LATENCY
End-to-end pipelines allow you to monitor and minimize end-to-end latency. This is achieved by using a single end-to-end pipeline schedule, which eliminates the need for an independent ingestion pipeline and dbt job-level schedules. When the schedule triggers the end-to-end pipeline, the ingestion processes will run. The dbt workflow will start only after the data for every table used in the dbt SQL models is up to date. This removes the need for additional scheduling components outside of Etleap, which reduces data stack complexity. It also ensures that all data involved in dbt transformations is at least as recent as the scheduled trigger time. Consequently, data in all the final tables or views will be up to date as of the scheduled trigger time.
AMAZON REDSHIFT WORKLOAD SYNCHRONIZATION
Due to pipelines and dbt builds running on the same schedule and triggering only the required parts of data ingestion and dbt transformations, higher workload synchronization is achieved. This means that customers using Redshift Serverless can further minimize their compute usage, driving their costs down further.
MANAGED INFRASTRUCTURE
One of the challenges when using dbt Core is the need to set up and maintain your own infrastructure in which the dbt jobs can be run efficiently and securely. As a software as a service (SaaS) provider, Etleap provides highly scalable and secure dbt Core infrastructure out of the box, so there’s no infrastructure management required by your data teams.
SOLUTION OVERVIEW
To illustrate how end-to-end pipelines can address a data analytics team’s needs, we use an example based on Etleap’s own customer success dashboard.
For Etleap’s customer success team, it’s important to track changes in the number of ingestion pipelines customers have. To meet the team’s requirements, the data analyst needs to ingest the necessary data from internal systems into an Amazon Redshift cluster. They then need to develop dbt models and schedule an end-to-end pipeline. This way, Etleap’s customer success team has dashboard-ready data that is consistently up to date.
INGEST DATA FROM THE SOURCES
In Etleap’s case, the internal entities are stored in a MySQL database, and customer relationships are managed via HubSpot. Therefore, the data analyst must first ingest all data from the MySQL user and pipeline tables as well as the companies entity from HubSpot into their Amazon Redshift cluster. They can achieve this by logging into Etleap and configuring ingestion pipelines through the UI.
DEVELOP THE DBT MODELS
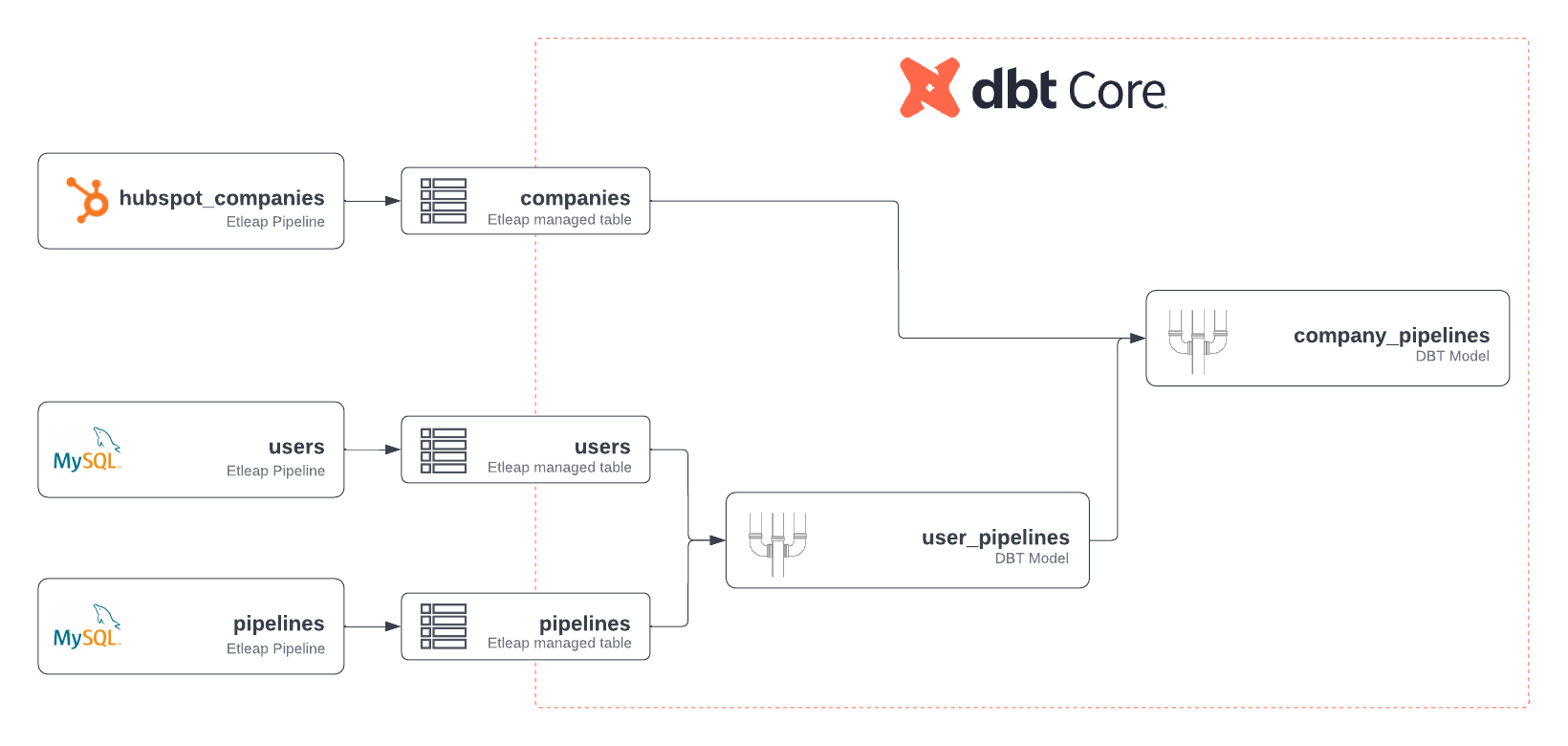
After the data has been loaded into Amazon Redshift, the data analyst can begin creating dbt models by using queries that join the HubSpot data with internal entities. The first model, user_pipelines.sql, joins the users table with the pipelines table based on the foreign key user_id stored in the pipelines table, as shown in the following code. Note the use of source notation to reference the source tables, which were ingested using ingestion pipelines.

The second model, company_pipelines.sql, joins the HubSpot companies table with the user_pipelines table, which is created by the first dbt model, based on the email domain. Note the usage of ref notation to reference the first model:

After creating these models in the dbt project, the data analyst will have achieved the data flow summarized in the following figure.
TEST THE DBT WORKFLOW
Finally, the data analyst can define a dbt selector to select the newly created models and run the dbt workflow locally. This creates the views and tables defined by the models in their Amazon Redshift cluster.
The resulting company_pipelines table enables the team to track metrics, such as the number of pipelines created by each customer or the number of pipelines created on any particular day.
SCHEDULE AN END-TO-END PIPELINE IN ETLEAP
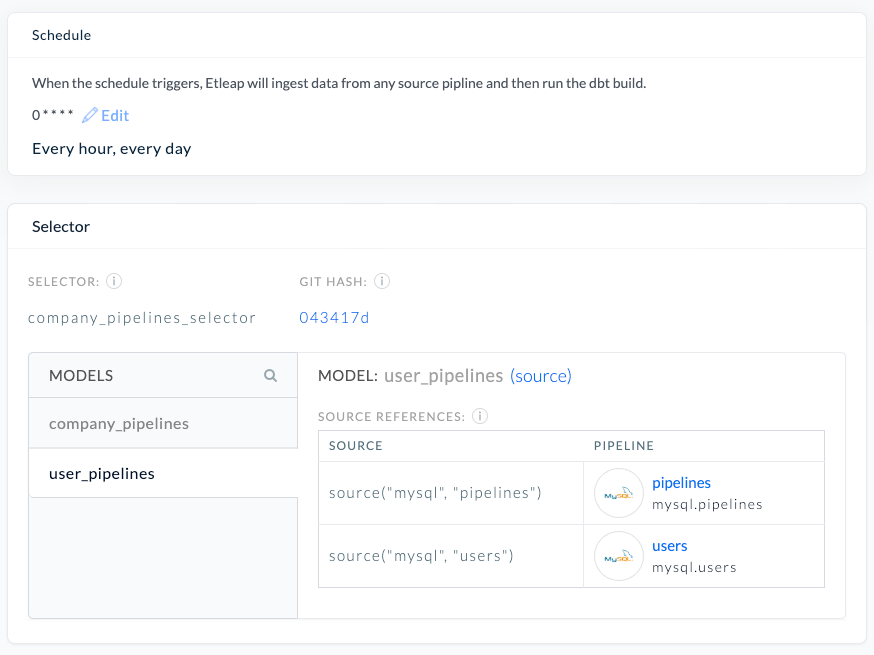
After the data analyst has developed the initial models and queries, they can schedule an Etleap end-to-end pipeline by choosing the selector and defining a desired cron schedule. The end-to-end pipeline matches the sources to pipelines and takes care of running the ingestion pipelines as well as dbt builds on a defined schedule, ensuring high freshness of the data.
The following screenshot of the Etleap UI shows the configuration of an end-to-end pipeline, including its cron schedule, which models are included in the dbt build, and the mapping of inferred dbt sources to Etleap pipelines.
SUMMARY
In this post, we described how Etleap’s end-to-end pipelines enable data teams to simplify their data integration and transformation workflows as well as achieve higher data freshness. In particular, we illustrated how data teams can use Etleap with dbt and Amazon Redshift to run their data ingestion pipelines with post-load SQL transformations with minimal effort required by the team.
Start using Amazon Redshift or Amazon Redshift Serverless to take advantage of their powerful SQL transformations. To get started with Etleap, start a free trial or request a tailored demo.
ABOUT THE AUTHORS
 Zygimantas Koncius is an engineer at Etleap with 3 years of experience in developing robust and performant ETL software. In addition to development work, he maintains Etleap infrastructure and provides deep-level technical customer support.
Zygimantas Koncius is an engineer at Etleap with 3 years of experience in developing robust and performant ETL software. In addition to development work, he maintains Etleap infrastructure and provides deep-level technical customer support.
 Sudhir Gupta is a Principal Partner Solutions Architect, Analytics Specialist at AWS with over 18 years of experience in Databases and Analytics. He helps AWS partners and customers design, implement, and migrate large-scale data & analytics (D&A) workloads. As a trusted advisor to partners, he enables partners globally on AWS D&A services, builds solutions/accelerators, and leads go-to-market initiatives.
Sudhir Gupta is a Principal Partner Solutions Architect, Analytics Specialist at AWS with over 18 years of experience in Databases and Analytics. He helps AWS partners and customers design, implement, and migrate large-scale data & analytics (D&A) workloads. As a trusted advisor to partners, he enables partners globally on AWS D&A services, builds solutions/accelerators, and leads go-to-market initiatives.