We’re excited to launch Apache Iceberg as a data destination in Etleap! This milestone is the culmination of innovative development by our product engineering team and marks the beginning of a new chapter in Etleap’s journey. In this post, we’ll explore what Iceberg is, why it’s a game-changer for ETL, and how it can benefit your data workflows.
Key Benefits of Iceberg in Etleap
- Ultra-Fresh Data: Improve data freshness from minutes to seconds.
- Unified Storage: Simplify data management by storing it just once for data lake and warehouse use cases.
- Open Format: Store data in an open format for greater interoperability and accessibility.
Apache Iceberg unifies data lakes and warehouses by creating a combined storage layer using an open data format supported by AWS and Snowflake. This enables us to significantly enhance data freshness: reducing latency from minutes to mere seconds.
Below is a screenshot from an Etleap pipeline that is ingesting data from a Postgres database to Iceberg, which is connected to a Snowflake data warehouse. Despite handling over 4B records, the data available for querying in the destination warehouse is only seconds old.

Figure 1: An Etleap pipeline showing rapid data ingestion from a large Postgres table to Iceberg, with data available in Snowflake in seconds.
The Evolution of Data Freshness
Rewinding about 15 years, before data warehousing moved to the cloud, ETL would run once per day - typically overnight. The process itself would take hours because it encoded business logic and would run complex procedures to update the destination warehouse tables. Then along came cloud data warehousing with Amazon Redshift and Snowflake, which made data warehousing affordable and ubiquitous. New cloud ETL vendors (including Etleap!) took advantage of the performant ingestion mechanisms offered by these warehouses and turned data ingestion into process that could run every hour or even more frequently. That change, coupled with post-load transformation (ELT), popularized by tools like Looker and dbt, that takes advantage of cloud warehouse performance, enabled a whole new set of analytics use cases that could operate on same-day data.
During the same period companies have built out data lakes. This was done initially with Hadoop, Spark, and Presto, and more recently on AWS’s and Databricks’ platforms. Storage layers for the lakes and warehouses have been mostly separate, with data lakes traditionally built directly on object stores such as HDFS and S3, and warehouses using the warehouse’s internal and proprietary formats.
As cloud data warehousing for operational use cases has grown so has the need for data to be even more up-to-date. Before generative AI took over the conversation, a recent AWS re:Invent conference introduced the term “zero ETL”. The idea of “zero ETL” is that you can have mirrors of your data stores available in your data warehouse or lake without the added detour and latency of a data pipeline. Of course, AWS’s “zero ETL” offering only works if you’re using a supported AWS service both on the source and destination side and the term itself is a bit of a misnomer since there is still a data pipeline under the hood: it’s just abstracted away from you. However, the idea that you can think of a source as instantly mirrored to your lakehouse is clearly powerful.
Put simply, cloud data warehousing improved freshness from a day to a fraction of an hour and with Iceberg, Etleap is cutting it down to just seconds. We believe that low-latency ingestion via Iceberg achieves the benefits of “zero ETL” without requiring your data be subjected to proprietary data formats, opening up more opportunities for data consumption.
Unified Storage: The Future of Data Management
For years, data teams have often operated both a lake and a warehouse: where data is first ingested into a lake and then a warehouse is built on top of that. This way data is accessible from the data lake (AWS S3 and Glue) for use cases like ad-hoc querying (Trino/Athena) and machine learning (Spark, SageMaker, Databricks), and from the warehouse for fast queries, e.g. for BI. A common pattern used by Etleap customers is to ingest data into an AWS Data Lake destination first and then from there ingest some data into their Snowflake or Redshift data warehouse (often via external tables and dbt models).
A major downside to this approach is that a data lake is inherently append-only. This means that unless you implement a sophisticated data management policy where data is periodically compacted or reduced, you end up with more and more data to access, making access slower and slower. Another downside is that it means you’re storing the data in two different places which leads to governance and management complexities.
The solution to these problems is straight-forward in theory: store huge amounts of data in a way that makes data management easy and enables fast access from both the lake and the warehouse. The devil is in the (implementation) details, and Apache Iceberg not only has an answer to the challenges with techniques like hidden partitioning, atomic updates, equality deletes, and merge-on-read, but has gained adoption from giants in the space, including AWS and Snowflake.
Iceberg is supported by Snowflake, Redshift, and Athena. Snowflake has published a blog post stating that query performance with Iceberg tables is similar to that of native Snowflake tables. The query performance we have seen in our initial testing across these platforms has been very encouraging (benchmarks coming soon!).
Building a Solution with Iceberg
We chose operational SQL databases as the first type of source we wanted to support for Iceberg for a few reasons. First and foremost our customers have been pushing us for the past few years to increase the freshness of the data from these sources in their data warehouses to support operational use cases where the usefulness of the data deteriorates quickly with time. A secondary reason is that databases offer the most challenging types of data from a data ingestion perspective due to the combination of updates, deletes and insertions, and that any part of the data set can change, unlike time series or reporting data where typically only the last day, week, or month is changing and prior data stays constant. Databases are a great benchmark for evaluating how well this solution stacks up against our existing approaches to data ingestion.
We set out to achieve 5 second freshness for databases. This means that data should be available for (fast) queries via your favorite query engine 5 seconds after it is committed to the source database. While this is not real-time in the strictest sense, this does get close to the freshness you would expect from an asynchronous read replica in an operational database setup. Unlike a database read replica, of course, the query engine here promises fast analytical queries on huge datasets.
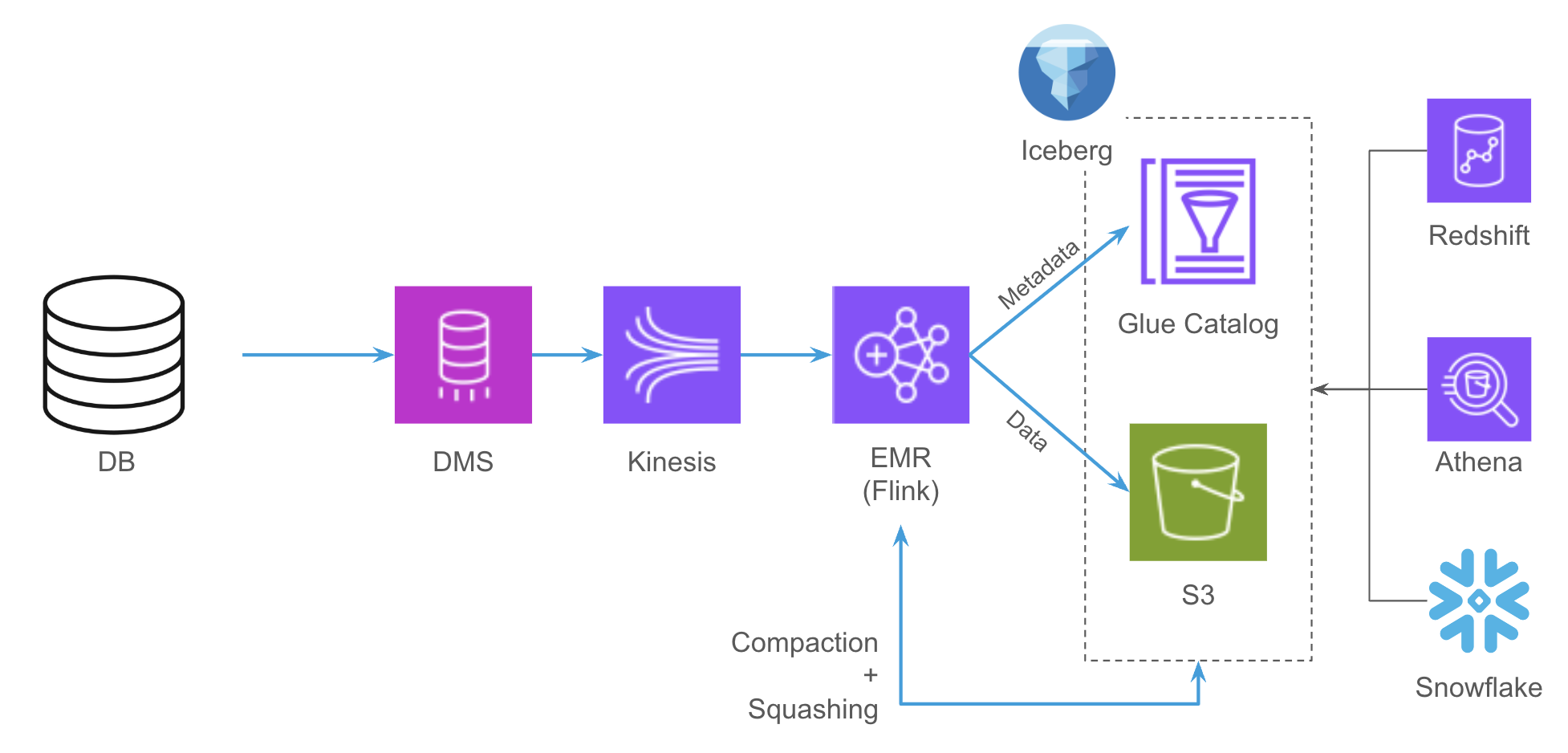
Our solution, illustrated below, involves the following key components:
- A data flow using AWS services: DMS, Kinesis, EMR, Glue catalog, and S3.
- A Flink application for real-time data transformation and writing to Iceberg tables, refreshing metadata in Snowflake when necessary.
- A secondary Flink application for periodic data compaction to optimize storage.

Figure 2: Technical architecture of Etleap's Iceberg integration.
Our setup ensures exactly-once processing, online schema changes, elasticity, and high scalability. Initial testing shows the setup handles up to 10,000 changes per second per table, and we expect this number to get higher with additional tuning.
Customers testing our solution during the alpha phase report low-latency queries from both Snowflake and Amazon Redshift.
What’s Next?
While formal benchmarks are being constructed, we have observed that Snowflake, Redshift, and Athena do a good job of using metadata from Iceberg to reduce the amount of data required to be read from S3. This bodes well for a potential future where companies can store all their data in Apache Iceberg instead of having to ingest some of it into a warehouse-native format. We’ll be following performance closely and doing our part to keep Iceberg tables optimized for maximum query speeds. Up next at Etleap we are extending Iceberg support to sources beyond SQL databases.
Conclusion
By using Iceberg as a destination in Etleap, you get long-term data storage in an open format supported by Snowflake and a wide range of AWS services, while retaining the fast query access you expect from Snowflake and Amazon Redshift.
Ready to experience the future of ETL? Sign up for a free Etleap trial today and transform your data workflows!