
tl;dr: This post is about how to split and process CSV files in pieces! Newline characters within fields makes it tricky, but with the help of a finite-state machine it’s possible to work around that in most real-world cases.
Comma-separated values (CSV) is perhaps the world’s most common data exchange format. It’s human-readable, it’s compact, and it’s supported by pretty much any application that ingests data. At Etleap we frequently encounter really big CSV files that would take a long time to process sequentially. Since we want our clients’ data pipelines to have minimal latency, we split these files into pieces and process them in a distributed fashion.
At this point you’re probably wondering what the problem is – CSVs are pretty simple, and it’s really easy to write a parser for it, right? Well, yes, as it does have a context-free grammar (at least according to the most popular CSV standard, RFC 4180). The challenge is splitting, in other words, how do parse the file when you’re reading from a point in the file that is not the beginning.
Again, you might be wondering why a blog post on this is interesting when splitting files on newlines is a feature that’s been built into Hadoop for ages. Here’s how Hadoop does it: It assigns responsibility for byte ranges of the file to independent processes, called “map tasks”. Each map task scans until the next newline after its byte boundary, and starts processing data from that point onwards (unless the map task is reading from the beginning of the file, in which case it starts processing data from byte 0). Similarly, at the end of the byte range, the map task processes data up to the first newline after the end. This way, all the data gets processed exactly once overall with minimal extra IO work.
This would work for CSV files had it not been for the fact that CSV files can have newlines embedded within fields. In other words, when the map task starts scanning its input split, it’s not sufficient to look for the next newline to decide where to start producing input records, since that newline might be part of a field value as opposed to a record delimiter. Looking for the next quote also won’t work, as there’s no definite way of knowing whether that quote is the beginning or end of a field.
So if looking for a newline or a quote won’t work, how will the map task decide where the next record beings? Let’s look at a finite-state machine for CSV files (we’re assuming the file format follows RFC 4180). At any point in the file, you can either be within a quoted field or within a non-quoted field, so these are natural candidates for states. You can also be at the end of a field (i.e. after a comma), or at the end of a record (i.e. after a newline). In order to allow for single-character state transitions, one more state is necessary: when you’re in a quoted field and you see a quote. In that case, the quote might either signify the end of the quoted field, or an escaped quote (if the next character is a quote). Our alphabet consists of newline (CR or LF), comma, quote, and a character class containing all other symbols, and the resulting finite-state machine (FSM) is shown below.
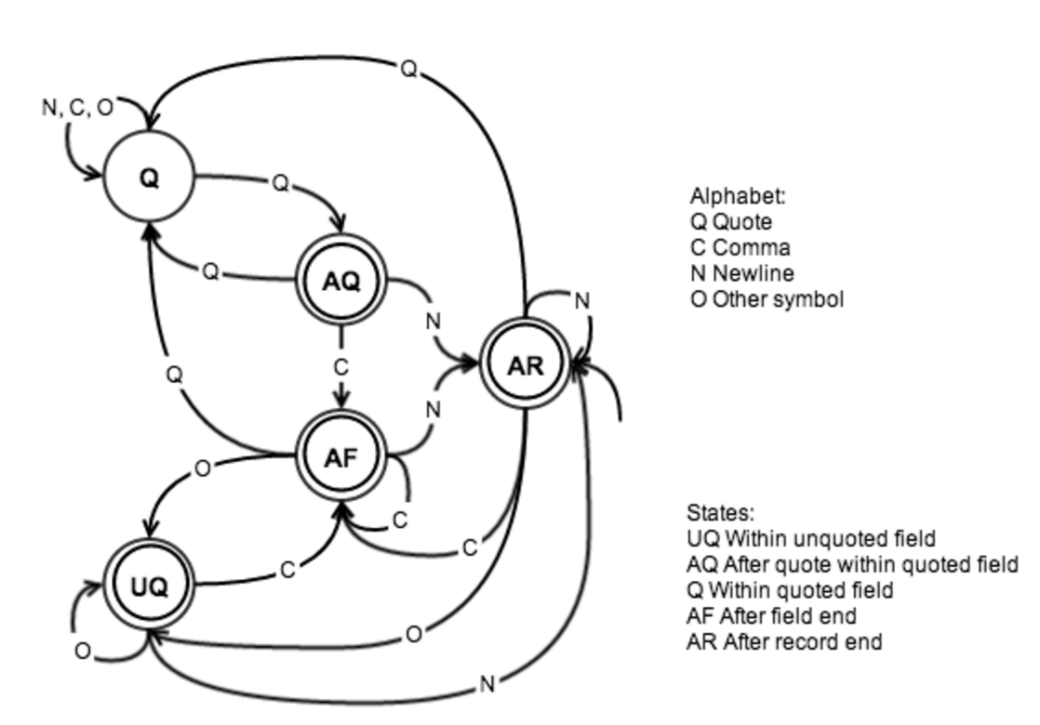
Figure 1: Finite-state machine for CSV files. AR is the start state, and all states except Q are accepting
The content of a CSV file will be accepted if and only if it is accepted by this FSM. Note that there are symbols that aren’t allowed in certain states, such as a quote symbol (Q) within an unquoted field (UQ). As is illustrated above, AR is the start state, since being at the beginning of a CSV file is like just having finished a record from a parsing perspective.
The reason why I’m bringing up the FSM of a CSV file is that it turns out to be useful for finding the next record when parsing a piece of a CSV file. The general idea is to assume when we’re starting from a point in the file that is not the beginning that we could be in any of the five states above. As we start consuming character input, that gives us five possible next states. However, as you can see from the transition function table below, there are only two possible states after consuming the first input symbol.
| State \ Symbol | Q | O | N | C |
| Q | AQ | Q | Q | Q |
| AQ | Q | – | AR | AF |
| UQ | – | UQ | AR | AF |
| AF | Q | UQ | AR | AF |
| AR | Q | UQ | AR | AF |
After the first symbol, we can simply follow the two paths until we find one of the two paths to be invalid, that is we encounter a non-special character (O) from the AQ state or a quote character (Q) in the UQ state. The path that is left “wins”, and the first byte for processing is the one after that path’s first entry into AR – this is similar to how Hadoop works for text files, as described earlier. The input up until that point in the file will have been consumed by the task processing the previous file split. Note that because of the observation above about the state after the first symbol we can use the two states Q and AR as representative starting states.
CSVs Without Quotes
So is that it? Well it turns out we’re not quite done. A map task can read the input only once so we have to keep in memory the input we read for the purpose of figuring out the starting point until we know what to process. Since memory is a scarce resource we have to place a bound on that memory buffer, which could lead to not finding the starting point. This isn’t necessarily just something that happens in edge cases – consider for example the case where the CSV doesn’t have any quotes at all: The path that starts in Q will stay in that state forever, whereas the other path will follow a path involving UQ, AF, and AR. To get around this problem we could place a maximum allowed record length, and set our buffer size accordingly. The FSM below accepts CSVs with a maximum record length of N characters. Note that commas and quotes also contribute to the record length in this model.
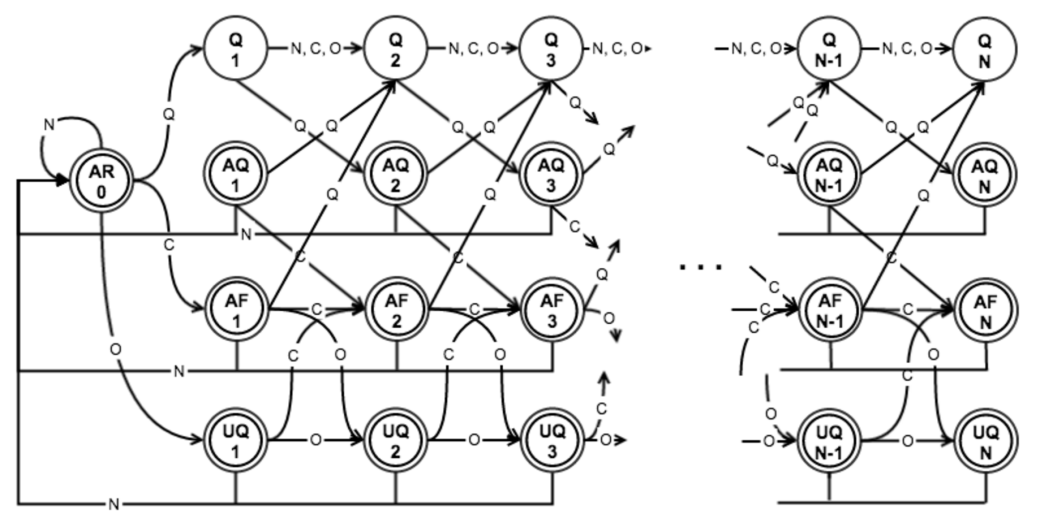
Figure 2: Finite-state machine for CSV files with a maximum record length.
The key difference from the FSM in figure 1 is that for each of the states Q, AQ, AF, and UQ there is one state per current record length, denoted by the number underneath the state name in figure 2. As you can see, only the newline symbol is valid when the record length is N. To avoid the problem caused by CSVs without quotes, we simply follow the paths from Q1 and AR0 in the modified FSM until one of them is rejected.
Inherently ambiguous substrings
I wish I could say that this was it, that implementing the logic above would give us a known starting point in all cases. Unfortunately, there are still corner cases where it fails. Here’s a somewhat contrived example: Consider a CSV file that consists of a quote followed by newline over and over again, and imagine what would happen if you started reading in the middle of such a file. Say the first symbol you see is a newline: Is that newline is a record delimiter or embedded within a quoted field? Our paths from above go into infinite loops:
Q1 → Q2 → AQ3 → AR0 → Q1 → … and AR0 → AR0 → Q1 → Q2 → AQ3 → AR0 → …
The good news is that these are really rare in real-world data sets. When they do occur, we can fail our processing job and default back to not splitting the CSV file.
Conclusion
By using this method of unambiguously locating the first record in a piece of a CSV file, we can take advantage of Hadoop’s task distribution, and process big CSV files in parallel when possible. We can also determine if parallel processing is not possible and fall back to sequential processing.