This article was also posted on AWS’s blog here.
By Christian Romming, Founder and CEO at Etleap
Neeraja Rentachintala, Principal Product Manager with Amazon Redshift
Jobin George, Sr. Partner Solutions Architect at AWS
Caius Brindescu, Member of Technical Staff at Etleap
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing extract, transform, and load (ETL), business intelligence (BI), and reporting tools.
Tens of thousands of customers use Amazon Redshift to process exabytes of data per day and power analytics workloads such as BI, predictive analytics, and real-time streaming analytics.
In this post, we discuss how Etleap integrates with new data sharing and cross-database querying capabilities in Amazon Redshift to enable workload isolation for diverse analytics use cases in customer environments.
Etleap is an AWS Advanced Technology Partner with the AWS Data & Analytics Competency and Amazon Redshift Service Ready designation.
Introduction to Etleap and New Amazon Redshift Capabilities
Etleap is a fully-managed ETL solution built specifically for Amazon Web Services (AWS) that doesn’t require extensive engineering work to set up, maintain, and scale. It reduces ETL setup time from months to days, automates most maintenance work, and provides transparency and full control over data pipelines.
Etleap integrates with any data source and runs either as a hosted solution (SaaS) or inside your virtual private cloud (VPC).
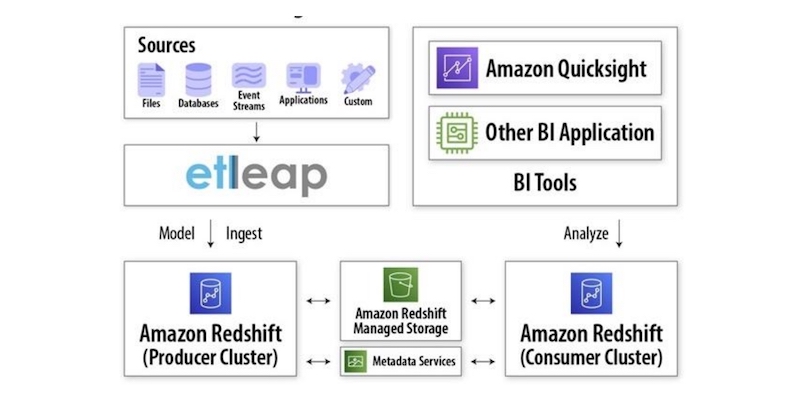
The new cross-database query capability in Amazon Redshift allows customers to query across databases in an Amazon Redshift cluster using a simple three-part notation <database>.<schema>.<table>.
Customers will continue to connect to a specific Amazon Redshift database from their BI and analytics tools, and applications via JDBC/ODBC similar to how they do today. Now, however, they can seamlessly query data from all the databases they have permissions to access on the cluster without having to connect to one database at a time.
The new Amazon Redshift data sharing capability allows customers to securely and easily share data across different Amazon Redshift clusters. Data sharing improves the agility of organizations by giving them instant, granular, and high-performance access to live data across Amazon Redshift clusters without the need to manually copy or move it.
Once data is shared, customers can use cross-database query functionality to query the shared databases from the consuming clusters and join the shared data with local data on the consumer cluster.
Why Etleap Customers Need Amazon Redshift Data Sharing
The workloads that Etleap users run on Amazon Redshift can be broadly divided into three categories:
- Ingestion – Etleap connects to data sources such as databases, applications, files, web services, and event streams, transforms data according to user-specified rules, and loads data into customer’s Amazon Redshift clusters. The load itself consists of COPY statements, and also typically joins with target tables in order to perform UPDATEs and DELETEs of existing records.
- Modeling – Users create Amazon Redshift materialized views through Etleap models, which are specified through SELECT statements that join and aggregate data. These materialized views ensure queries that power reports and dashboards are performant. For a deeper analysis of the performance benefits of materialized views, see this post from the AWS Big Data Blog.
- Analytical Queries – These come in many forms—for example ad-hoc analyses, internal or customer-facing dashboards, and scheduled reports. These workloads are read-heavy, consisting mostly of SELECT queries.
We’ll refer to the first two categories (ingestion and modeling) as ETL workloads, and the third category (analytical queries) as BI workloads.
BI workloads require data to have been ingested and modeled. BI users expect their data to be available and up-to-date, often have a low tolerance for data delays, and also cannot miss performance SLAs for critical reporting needs.
In order for data to be up-to-date, ETL processes that ingest and model data need to consistently run on time. There are two issues related to this that Amazon Redshift data sharing helps address.
Workload Variability
ETL workloads tend to be predictable in that they are executed on a schedule. Also, with users moving from nightly to continuous data ingestion and modeling, ETL workloads need to execute more constantly throughout the day as well.
BI workloads, on the other hand, tend to be more dynamic and variable throughout the day. When cluster capacity is shared between ETL and BI workloads, BI workloads can reduce the resources available to ETL because of this variability, delaying ingestions and modeling. These data delays can worsen the BI user’s experience.
There are also scenarios where BI clusters don’t get the necessary resources due to resource contention from ETL and query performance for BI users is impacted.
Different types of workloads also tend to have different data access patterns (for example, small queries from dashboarding applications vs. aggregations from analysts vs. large data processing for ETL) and different SLA requirements.
There may also be different teams responsible for ETL vs. BI, and each team may want to control the compute resources they want to provision for their workloads. Having separate clusters between ETL and different types of BI workloads is therefore beneficial.
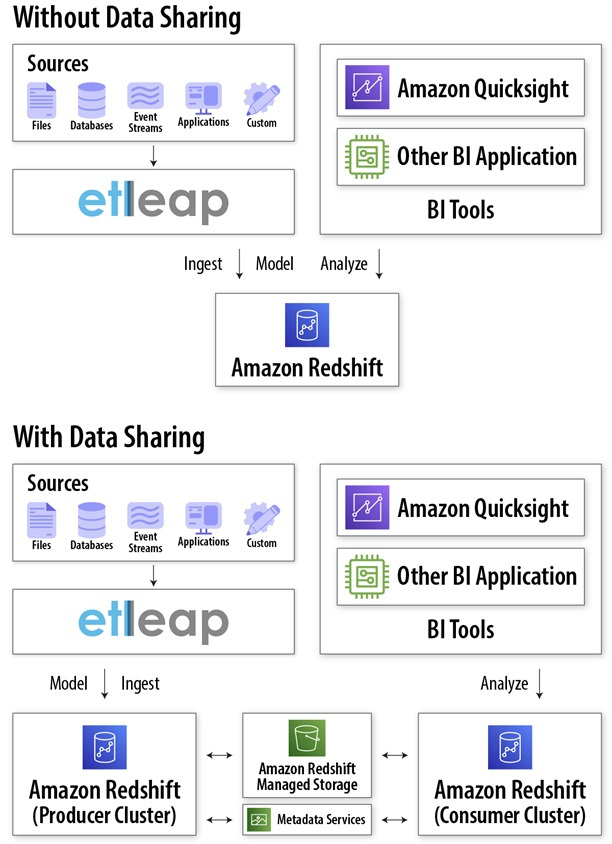
By using Amazon Redshift data sharing to isolate ETL and BI workloads to separate clusters, ETL workloads are not affected by BI workload variability, and BI users have up-to-date data and consistent SLAs for their analyses.
Another benefit of this separation is that ETL and BI cluster capacity can be provisioned according to their workload-specific performance requirements, and can be changed independently as requirements change. Data sharing also enables the ability to offer charge-back capabilities for various workloads and teams.
Table Locking
While Amazon Redshift is designed to enable concurrent reads and writes, Etleap often needs to run DDL operations, such as ALTER TABLE and DROP TABLE, in order to apply schema changes and complete full refreshes of ingestion pipelines.
Such DDL operations acquire an AccessExclusiveLock on the table in question, which means it cannot be accessed concurrently by readers. This can lead to contention between ETL and BI workloads.
Using Amazon Redshift data sharing to isolate BI workloads to a consumer cluster solves this problem. Data sharing provides snapshot isolation so consumers continue to query the data even when DDL is happening in producer.
Note there are no data movement as a result of data sharing—live and transactional data is simply shared in place through Amazon Redshift managed storage. This is illustrated in the following diagram.
Configuring Amazon Redshift Data Sharing with SQL Queries
Here’s an example of how to configure data sharing. We have configured a process to ingest click logs from our website stored in an Amazon Simple Storage Service (Amazon S3) bucket into our Amazon Redshift producer cluster.
The data is stored in a table called “clicks” in the schema “website” in the database “etl.” We want to share this table with the consumer cluster and grant read access to BI users, which are members of a group in the consumer cluster called “bi_users.”
First, we’re going to set up the datashare itself. For that we need the namespaces of both the producer and consumer clusters, so we run the following query on both clusters:
SELECT CURRENT_NAMESPACE;
Let’s assume the results are “producer_cluster” and “consumer_cluster,” respectively. On the producer cluster, we create the datashare and grant the consumer cluster access to it:
CREATE DATASHARE “etl_to_bi”;
GRANT USAGE ON DATASHARE “etl_to_bi” TO NAMESPACE ‘consumer_cluster’;
Next, we accept the datashare on the consumer cluster by creating a database from it:
CREATE DATABASE “etl_to_bi” FROM DATASHARE “etl_to_bi” OF NAMESPACE ‘producer_cluster’;
Now that we have the datashare established, let’s add the “website” schema and “clicks” table to it on the producer cluster:
ALTER DATASHARE “etl_to_bi” ADD SCHEMA “website”;
ALTER DATASHARE “etl_to_bi” ADD TABLE “website”.”clicks”;
Finally, on the consumer cluster, we can now add the shared schema to our database and grant permissions to our BI users.
CREATE EXTERNAL SCHEMA “website” FROM REDSHIFT DATABASE ‘etl_to_bi’ SCHEMA “website”;
GRANT USAGE ON SCHEMA “website” TO GROUP bi_users;
The “clicks” table is now available for querying by BI users, and, as the table is updated with new data in the producer cluster, it’s immediately available in the consumer cluster as well.
In some scenarios, we need to replace the table on the producer cluster because we’re re-ingesting the data. In this case, we’ll remove the table from the data share and add it back after we have recreated it.
From a consumer point of view, nothing needs to be done and the latest objects are available in the data share automatically in a transactionally consistent fashion.
ALTER DATASHARE “etl_to_bi” REMOVE TABLE ”website”.”clicks”;
DROP TABLE ”website”.”clicks”;
CREATE TABLE ”website”.”clicks” ...
ALTER DATASHARE “etl_to_bi” ADD TABLE “website”.”clicks”;
We don’t need to configure the access privileges on the consumer side again, as the access permissions are granted at the schema level. Note that for every new table that’s added to the schema on the producer side, we need to add the table to the datashare as described above.
Also, for each new schema we want to share, we need to add it to the datashare and also grant usage privileges to it on the consumer side.
Configuring Amazon Redshift Data Sharing with Etleap
Etleap has introduced support for Amazon Redshift data sharing and manages sharing between ETL and BI Amazon Redshift clusters so users don’t need to run the data sharing SQL statements themselves, simplifying workflows for data availability.
Here’s how to configure the data pipeline described in the example above in Etleap, where data ingested into a producer cluster is shared to a consumer cluster using data sharing.
First, we create the consumer cluster connection and add the user group “bi_users,” as shown in the screenshot below.
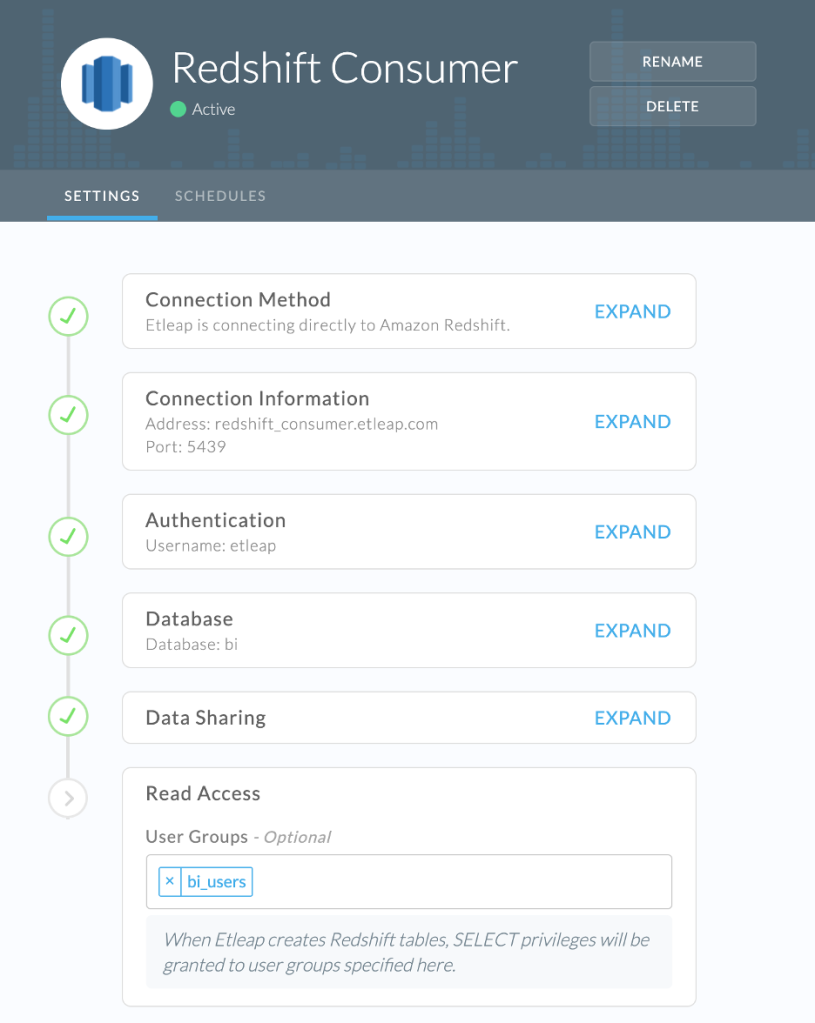
Figure 2 – Configuring the “bi users” group with read access to tables in the consumer cluster.
Then, we set up the producer cluster connection and, under “Data Sharing” we pick the consumer cluster from the dropdown.

Figure 3 – Configuring the producer cluster to share data with the consumer cluster.
At this point, Etleap has configured sharing from the producer cluster to the consumer cluster. The final step is to create an ingestion pipeline for the click data from Amazon S3 into the producer cluster, which involves going through Etleap’s pipeline setup wizard and interactive data wrangling.
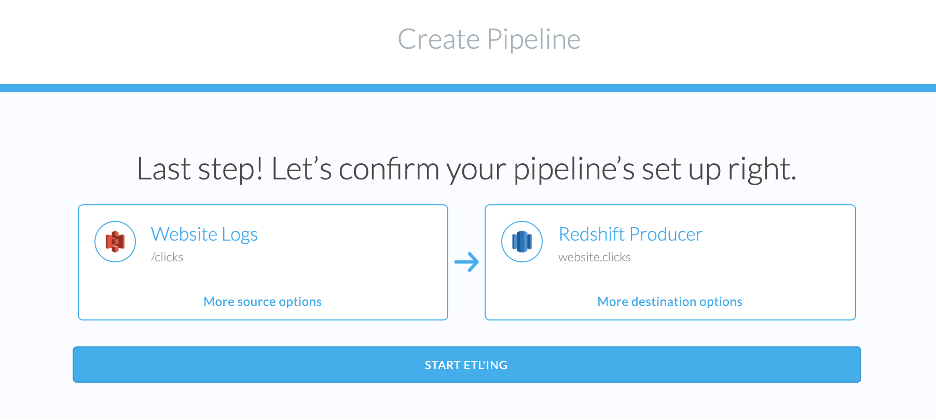
Figure 4 – Creating an Etleap pipeline to ingest data from S3 to the producer cluster.
Once we click “Start ETL’ing,” Etleap creates the “clicks” table in the producer cluster and continuously ingests new data into it as it becomes available. Etleap also adds the table to the datashare with the consumer cluster and configures read access to the “bi_users” group on the consumer cluster.
At this point, the table is ready to be queried by BI users.
Figure 5 – Querying the “clicks” table as a user in the “bi users” group on the consumer cluster.
As Etleap ingests new data into the “clicks” table, BI users will immediately and automatically see up-to-date data through Amazon Redshift data sharing. Note the data is not ingested into the BI cluster, but simply shared from the Amazon Redshift managed storage layer without any performance impact to the producer cluster.
Etleap maintains the datashare throughout the lifecycle of the ingestion pipeline, including cases where the producer table has to be recreated, so there’s no additional work required to maintain data sharing between the two clusters.
Summary
In this post, you learned about Amazon Redshift’s data sharing feature and how it helps achieve workload isolation and charge-ability. You also learned about the architecture of Amazon Redshift with the data sharing feature enabled, how data sharing can be configured using SQL commands, and how easy it is to leverage the capability in Etleap.
To learn more about Etleap, take a look at their Etleap ETL on AWS Quick Start, or visit their listing on AWS Marketplace.